浏览器怎样渲染一个页面?—— DOM,CSSOM及其渲染
在网页开发的过程中,影响用户体验的因素有很多,大部分归咎于资源加载速度慢、初始页面渲染时加载非必须的文件(甚至会出现没有样式的文档)等等。为了避免这些问题的产生,我们需要理解浏览器渲染一个特定的网页的整个周期和流程。
首先,我们需要搞清楚什么是 DOM。当一个浏览器向服务端请求一个 HTML 文档,服务器会将这个 HTML 文档以二进制形式的数据(一个带着 Content-Type = 'text/html; charset=UTF-8' 的text 文件)进行响应。这其中, text/html 是一种 MIME 类型(MIME 能够告诉浏览器这是一个 HTML 文档,并且字符编码是 UTF-8)。有了这个信息,浏览器就能将二进制文件转换成一个可理解的文本文件,如下图所示

如果这个响应头丢失,那么浏览器将无法对文件进行解析和渲染。当一切就绪,浏览器就可以对 HTML 文档进行解析。HTML 文档的样子通常如下面代码所示
1 |
|
在上面的 HTML 文档中,网页主要依赖 style.css 文件来给 HTML 元素提供样式,依赖 main.js 来进行一些 JavaScript 脚本代码的执行。有了 CSS 样式,我们的页面看起来会非常棒

但我们还是没有聊到重点——浏览器是如何将一个漂亮的页面从一个简单的只充满了文本 HTML 文件渲染出来的呢?接下来我们就聊聊 DOM、CSSOM 和渲染树(Render Tree)。
DOM(Document Object Model)
当浏览器解析 HTML 代码时,遇到像 html、body 和 div 等等的标签,会创建一个称作节点(Node) 的JavaScript 对象。最终,所有的 HTML 元素都会被转换成这样的节点。
HTML 元素都会有自己不同的属性(properties),相应的,节点对象会从不同的类被构造出来。例如 div 元素会被创建为一个 HTMLDivElement 类的节点实例(继承于 Node 类),如下图
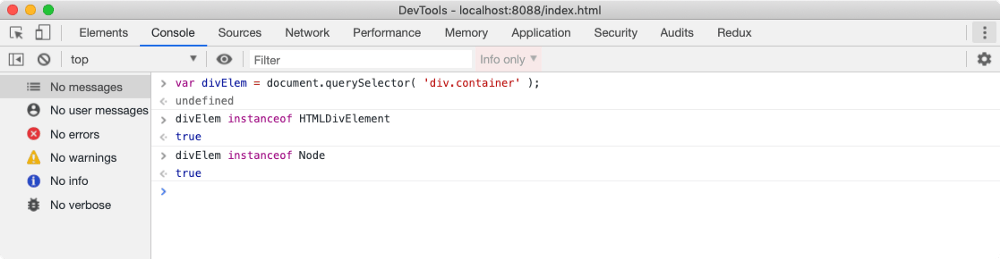
浏览器有很多这样内置的类,例如 HTMLDivElement、HTMLScriptElement 和 Node 类等等。
当浏览器解析完 HTML 文档并相应的创建出许多的节点后,还会将这些节点构建成为一个树状结构(如下图)。就想 HTML 文档中元素都是相互嵌套的,浏览器也需要相应的把这些节点构建成类似的嵌套的结构。这种结构会让浏览器更加高效的渲染和操作。
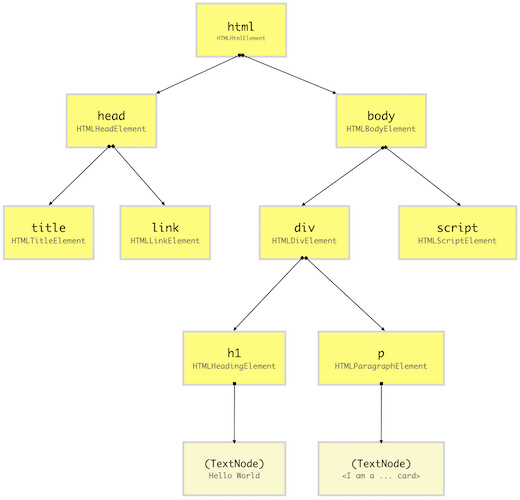
DOM 树的结构就如上图所示。一棵 DOM 树由 html 元素节点开始,其中的其他元素像树枝和叶子一样被层层嵌套(在 HTML 文档解析过程中,每当遇到一个 HTML 元素,就会从相应的节点类中构造出一个 DOM 节点并添加在 DOM 树上)。
DOM 节点并不总是 HTML 元素。当浏览器构建 DOM 树时,也会将注释、属性(attributes)和文本等保存成树上的节点。为了整个流程的简单描述,文中的节点我们都认为是由 HTML 元素创建的节点。点击这里查看所有的节点类型。
你可以在谷歌浏览器的 Devtools 控制台中可视化地查看 DOM 树的层级(如下图)。

JavaScript 是无法理解 DOM 是什么东西的。DOM 是浏览器为了搞笑渲染网页而向开发者暴露的 Web API,让开发者可以动态的去操作这些 DOM 元素。
开发者能够使用 DOM API 来进行 HTML 元素的添加和删除,改变其样式,为其绑定一些事件监听器。使用 DOM API 还能够在内存中人工创建和复制一些 HTML 元素,而不受已经渲染好的 DOM 树的影响。这些特性都让开发者为了提升用户体验而更好地开发动态网页。
CSSOM(CSS Object Model)
在设计一个网页时,我们会尽可能地让网页看起来更加美观。我们会在 HTML 元素中添加 CSS 样式来达到此目的。CSS 选择器让我们能够对选定的 DOM 元素设置类似 color 或 font-size 等的样式属性。
为元素添加样式有很多方法,有直接向 HTML 元素中添加样式(内联样式),或在 HTML 文档中添加 <style> 标签并在其中添加一些样式,也可以引入一个外部的 CSS 文件。最终,将 CSS 样式添加到 DOM 元素这个重担还是要落在浏览器身上。
针对上面提供的 HTML 文档,我们采用下面的 CSS 样式来进行美化。
1 | html { |
DOM 树构建完成后,浏览器将读取资源(外部的、内联的、HTML文档中的和用户代理)中的 CSS 样式文件,并构建出一个 CSSOM 树。CSSOM 意为 CSS Object Model,就和 DOM 树一样都是树结构。
在 CSSOM 树上,每一个节点都是针对一个 DOM 元素所包含的样式。而且,CSSOM 树不像 DOM 树(<meta>、<script>等)一样能够被打印在屏幕上。
用户代理样式,是大部分浏览器自带的一些样式表。浏览器在计算 CSS 样式属性时,会首先加载用户代理样式,然后会将开发人员提供的样式表(根据一定的 CSS 优先级规律)进行覆盖,来构造出每一个节点。
即使有的 HTML 元素没有用户代理和开发者提供特定样式,样式的默认值也会根据 W3C CSS 标准进行默认赋值。而一些元素的属性也会继承逐步继承这些默认的属性值。
例如,color 和 font-size 属性如果没有进行任何值的指定,他们会继承父元素的属性值。所以我们能够想象这些样式都是一层层进行继承和覆盖。这就是为什么样式表被称之为 CSS(cascading style sheets),这种规则也是浏览器能构建出 CSSOM 树的原因。
你能使用谷歌浏览器的 DevTools 控制台的 Elements 面板,在左侧选中一个 HTML 元素,点击后能够在右侧的 computed 面板中看到相应的样式计算结果。
我们将之前例子中的 CSSOM 树可视化为下面的图表。
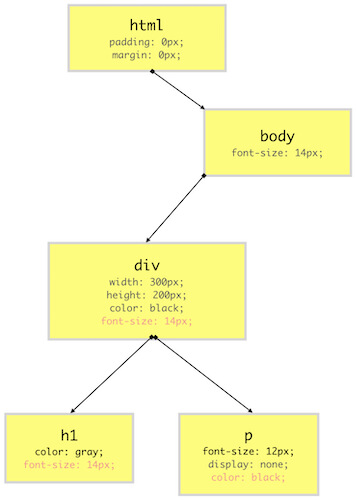
如上图所示,CSSOM 树是不包含能够打印出来的元素和标签的。上面红色的 CSS 属性和值就是从 body 元素上面的样式继承而来的,而 h1 标签的 color 属性则覆盖了其父元素 div 中的 color 属性。
Render Tree
渲染树也是一个树形结构,它结合了 DOM 树和 CSSOM 树。浏览器接下来需要计算每一个可见元素的布局并将其绘制在屏幕上,为了达到这一目的,浏览器需要用到 Render Tree。而 Render Tree 又是由 Dom 和 CSSOM 树得到的。
由于渲染树是能最终在屏幕上打印出的底层表示,它不会包含任何不包含像素矩阵面积的节点——例如使用了 display: none 样式的元素,这样的元素是不会出现在渲染树上的。

如上图所示,渲染树结合了 DOM 树和 CSSOM 树来构建出一个树形结构,这个树结构只包含能够最终绘制在屏幕上的元素。
上面代码中的 p 元素由于被设置了 display: none 样式,所以这个元素以及该元素的子元素都不会呈现在渲染树中,因为它不占任何屏幕空间。但是有一些例外,比如被设置了 visibility:hidden or opacity:0 样式的元素,他们虽然没有占据任何屏幕空间,但是仍然会被添加到渲染树上。
和 DOM API 能够让开发者去操控 DOM 元素不同,CSSOM 是被隐藏起来的,但由于渲染树结合了两者,所以浏览器通过提供高级的 DOM 上的 API 来暴露出 CSSOM 节点,这让开发者能够去操作和修改 CSSOM 节点的 CSS 属性。
本文不讨论怎样使用 JavaScript 脚本去操作元素的样式,这里仅提供描述了 CSSOM API 的链接 CSS Tricks Article。CSS Typed Object 一文提供了在 JavaScript 中更精确地操作元素样式属性的 API。
渲染流程
现在我们对 DOM,CSSOM 以及渲染树都有了一定的了解,接下来我们将揭露浏览器如何对一个网页进行渲染。对这个流程有一个简单的了解会让网站开发者提升网站的用户体验有极大的作用。
当一个页面加载时,浏览器首先会扫描 HTML 文档并构建出 DOM 树,然后会处理 CSS 文件(无论是内联还是外部的文件)并构建出 CSSOM 树。
当 DOM 树和 CSSOM 树构建出来之后,浏览器会结合两者来构建出渲染树。一旦渲染树构建完成,浏览器就能把每一个元素绘制在屏幕上。
布局(layout)
首先,浏览器会计算出每一个渲染树节点的布局。这里所说的布局包括这个节点的像素大小、以及绘制位置。这个过程被称作“布局(layout)“,有些时候也会被称作是回流(reflow)或浏览器回流(browser reflow)。回流是在用户进行滚动、缩放浏览器或操作 DOM 元素时会触发的。这里列举了一系列能够触发回流的事件和操作。
我们应当避免网页出现过多的布局和回流,因为这是一个极其消耗性能的操作。Paul Lewis 的文章讲述了一些如何避免复杂和消耗性能的操作。Layout thrashing 一文也可供参考。
绘制(paint)
目前我们已经有了一系列需要打印在屏幕上的文字和图案。由于渲染树上的元素有可能会彼此覆盖,甚至会有一些 CSS 属性让这些元素频繁的更改样式、位置等(例如动画),浏览器为此创建了图层(layer)。
图层让浏览器能够高效地进行绘制,无论是在网页上滑动还是缩放浏览器窗口。图层也能帮助浏览器正确地把元素以层叠的方式(开发者所需要的)进行绘制。
现在浏览器能够结合图层,将元素绘制在屏幕上了。但是,浏览器是不会一次性把所有图层绘制出来的,每一个图层都是有先后的绘制顺序。
在每一层中,浏览器会填充每一个可见属性的像素点(例如边框、背景颜色、阴影和文字等)。这个过程也被称作栅格化。为了提升性能,浏览器会使用不同的线程来进行栅格化操作。
这里的图层就像是 Photoshop 软件中的图层。你可以在 Chrome DevTools 中查看每一个不同的图层。打开 Chrome DevTools,在 more tools 选项中选择 Layers 标签。能够在 Rendering 面板上看到每一个层的边界。
栅格化一般都是由 CPU 来执行的,所以速度慢且成本高,但是现在出现的 GPU 技术能够很大程度提升这一步骤的性能。这篇 intel article 文章详细概括了绘制流程(尽量去阅读它!)。为了能够更加深入地理解图层,你需要查看这篇文章。
渲染层合并(compositing operation)
到现在,我们还没有在屏幕上绘制出任何一个元素。但是我们现在有了能够按照一定顺序绘制在屏幕上的一系列不同的图层。在渲染层合并这个流程里,这些图层将被送往 GPU 进行最终的绘制。
将所有的图层一起进行传输显然是低效的,因为每一次回流和重绘都需要全部发送一遍。所以每一个图层都被拆解为不同的块(tiles),这些块才是能够最终被绘制在屏幕上的单元。在 Chrome DevTools 的 Rendering 面板中也能够看到这些块。

上面画出了目前为止的所有渲染流程,也被称作 critical rendering path 。
Mariko Kosaka 写过一篇文章来详细讲述这一流程中的每一个概念(极力推荐)
浏览器引擎
DOM 树、CSSOM 树以及控制整个渲染的逻辑都是在一个被叫做浏览器内置的浏览器引擎(Browser Engine)(也被称作是渲染引擎或布局引擎)。这个浏览器引擎包含了所有将 HTML 文档渲染成为屏幕上的像素点所必须的元素和逻辑。
你听说过 WebKit 吗,这就是一个浏览器引擎。WebKit 是在苹果的 Safari 浏览器中,也是之前谷歌 Chrome 浏览器默认的渲染引擎。现在 Chromium 项目已经开始用 Blink 作为 Chrome 浏览器默认的引擎。这是一系列不同的浏览器对应的引擎。
浏览器的渲染过程
众所周知 JavaScript 是一种符合 ECMAScript 标准的语言,事实上由于 JavaScript 已经被注册为商标,我们现在都称其为 ECMAScript。所以,任何一种 JavaScript 引擎(包括 V8,Chakra,SpiderMonkey)都需要遵守这一标准。
这一标准让所有的 JavaScript 运行时环境(浏览器、Node、Deno等)一致的体验。这让 JavaScript 能够在多平台进行统一的应用开发。
然而浏览器渲染页面却很难提现这样的一致性,因为 HTML、CSS 和 JavaScript,这些语言都有自己独有的标准。所以 Chrome 和 Safari 浏览器在渲染流程上就有所不同。因此我们很难去预测不同浏览器背后所支持的渲染流程。但是 HTML5 规范对理论上如何渲染做出了一些努力,但是是否遵循这一规范不同的浏览器厂家也各有不同。
不管上面所提到的不同点,所有的浏览器在渲染过程其实遵循的规则大体上通常是一致的。我们这里就来了解一下浏览器渲染流程周期中共通的一些事件。为了更好地理解这个过程,下面准备了一个小的工程来测试不同的渲染场景。
course-one/browser-rendering-test
解析
文档解析是扫描 HTML 文档内容并构建 DOM 树的一个过程。所以这个解析也被称作是 DOM 解析,执行解析的程序被称作 DOM 解析器。
大多数浏览器都会提供 DOMParser Web API 来将 HTML 文档构建成 DOM 树。一个 DOMParser 类的实例代表一个 DOM 解析器,这个解析器使用 parseFromString 原型方法来将 HTML 文本解析成 DOM 树结构。
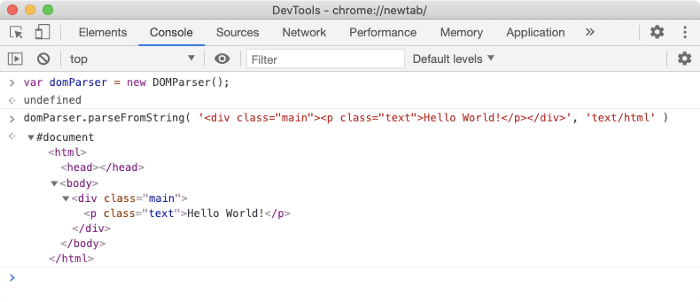
当浏览器向服务器请求并返回了一个 HTML 文档时,浏览器就可以开始解析这个文档。因此浏览器能够逐步地构建 DOM 树,一次构建一个节点。浏览器是从上到下地扫描 HTML 文档。
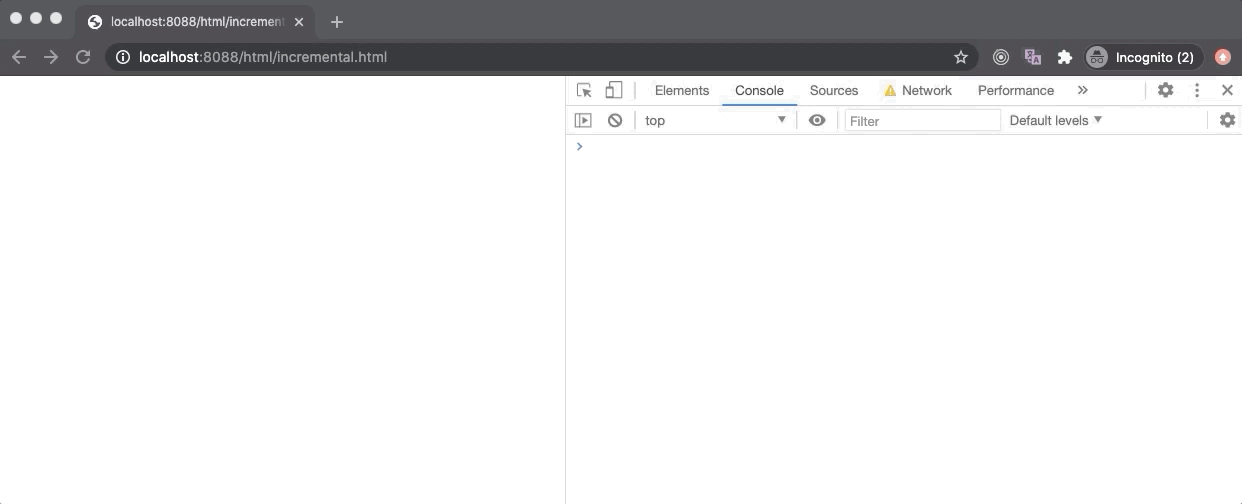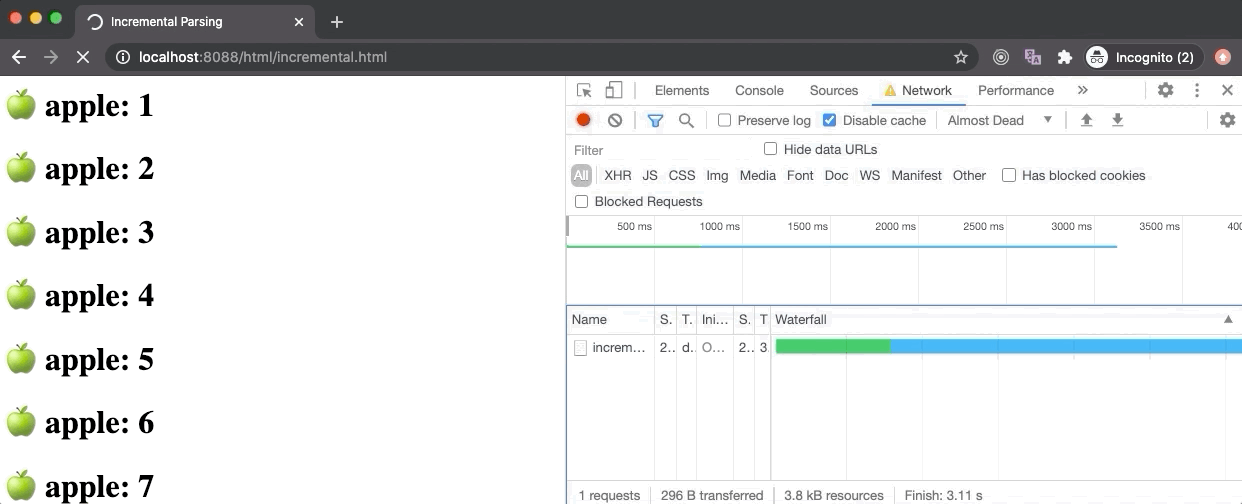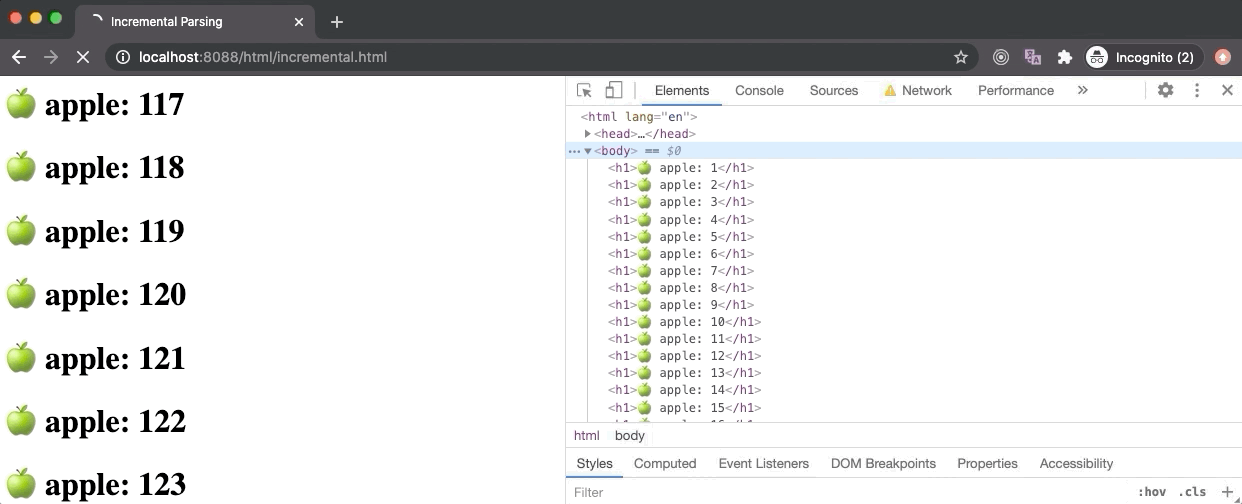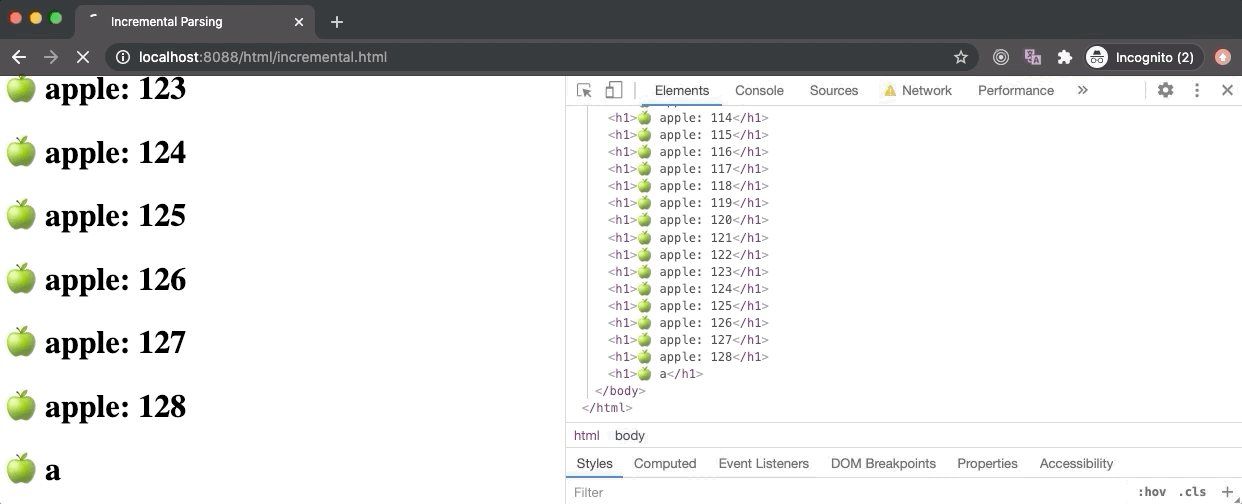
上图展示了在 Node 服务器上以 10kbps 的速度请求 incremental.html 文件。因为这个请求获取文件的过程需要很长一段时间,浏览器加载这个文件从一开始的一小部分代码就能够不断地增量渲染出节点。
如果你在 Chrome DevTools 中的 Performance 面板中查看上述请求,能够看到每一步流程的时序。这些事件都被称作是性能指标,当这些事件能靠的很近,那么说明用户体验会很好。
使用⟳按钮可以将某一个性能档案进行捕捉。
FP 代表着 First Paint,意思是浏览器开始绘制。FCP 代表着 First Contentful Paint,意思是浏览器开始绘制第一个像素点。LCP 代表着 Largest Contentful Paint,意思是浏览器渲染一大块文本或图像的时间。
你可能听过 FMP,代表着 First Meaningful Paint,与 LCP 指标类似,但是已经被 Chrome 弃用了。
L 代表着 onload 事件(浏览器在 window 对象上所触发的事件)。DCL 代表着 DOMContentLoaded 事件(在 document 对象上触发但是会冒泡到 window 对象)。因此可以监听 window 对象。这些事件有一些复杂,我们会简单介绍一下。
每当浏览器扫描到了外部的资源,比如一些 <script> 标签标示的脚本文件(JavaScript文件)或 <link> 引入的样式文件,亦或是图片元素,浏览器会开始在后台下载这些资源(而不是 JavaScript 执行的主线程)。
最重要的一点是要记住——DOM解析通常是在主线程上进行的。所以当 JavaScript 主线程忙时,DOM 解析会被挂起直到线程空闲。为什么 JavaScript 会阻塞 DOM 的解析?那是因为脚本元素是解析阻塞的(脚本会影响 DOM 树的生成),而样式表、图片、pdf和视频等静态资源文件则不会阻塞。
阻塞解析脚本
阻塞解析脚本指的是会让 HTML 文档解析阻塞的脚本文件。当浏览器遇到 script 标签时,如果是嵌入式脚本,脚本会被立即执行然后再继续解析 HTML 文档来构建 DOM 树。
如果遇到的 script 标签是一个引入的外部脚本文件,浏览器会在后台非主线程上开始下载这个脚本文件,在下载过程中,主线程的任务也是被暂时挂起的。在外部脚本没有下载完成之前,DOM 解析不会开始。
一旦脚本文件下载完成,浏览器会在首先主线程上执行这个脚本文件,然后开始 DOM 解析。浏览器再遇到相同的脚本标签,也会重复这一过程。为啥要这么做呢?这是因为浏览器将 DOM API 暴露给 JavaScript 运行时,这意味着我们可以使用 JavaScript 脚本来操控 DOM 元素。这也是 React 和 Angular 这些框架能够动态改变网页的原因。但是如果浏览器并行地解析 DOM 和执行脚本,可能会存在条件竞争漏洞(不知道到底哪个最终会影响 DOM 树的生成)。
但是很显然,在脚本下载的过程中暂停 DOM 的解析也是非常没有必要的,所以 HTML5 为 script 标签新增了 async 属性——当浏览器遇到了带有 async 属性的 script 标签,不会暂停解析过程并在后台下载脚本文件,但是当文件下载完成,解析过程会被挂起直到脚本被执行完。
另外,HTML5 还提供了 defer 属性,有点类似 async 属性,不同的是这种脚本在下载完成之后也不会立即执行。所有带 defer 属性的 script 标签,都会在后台并行下载,等到 HTML 解析完成,DOM 树构建完成,这些脚本才会被执行。
所有其他正常的 script 标签代表的脚本,都是阻塞解析的脚本。所有 async 脚本都是下载期间不阻塞解析,下载完成后阻塞解析。而 defer 脚本是无论如何都不会阻塞 DOM 解析的。
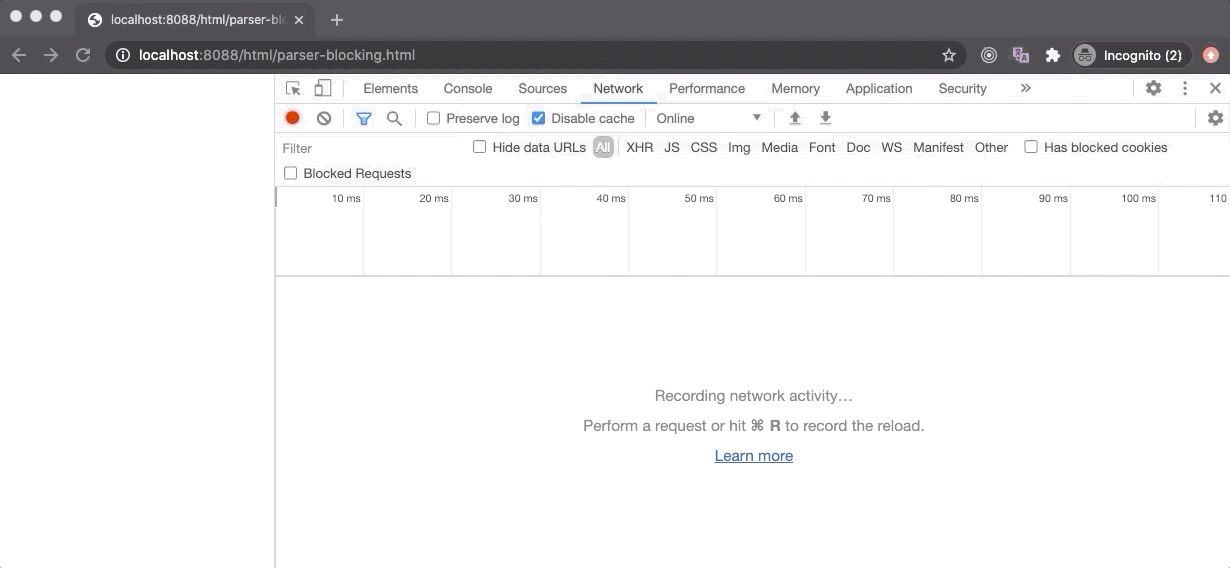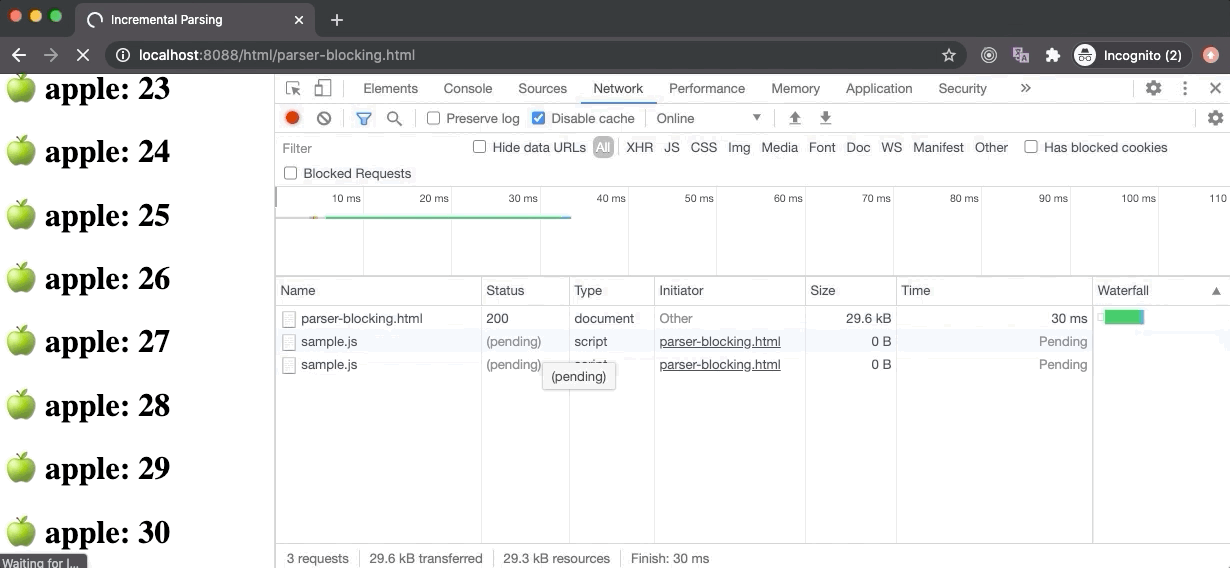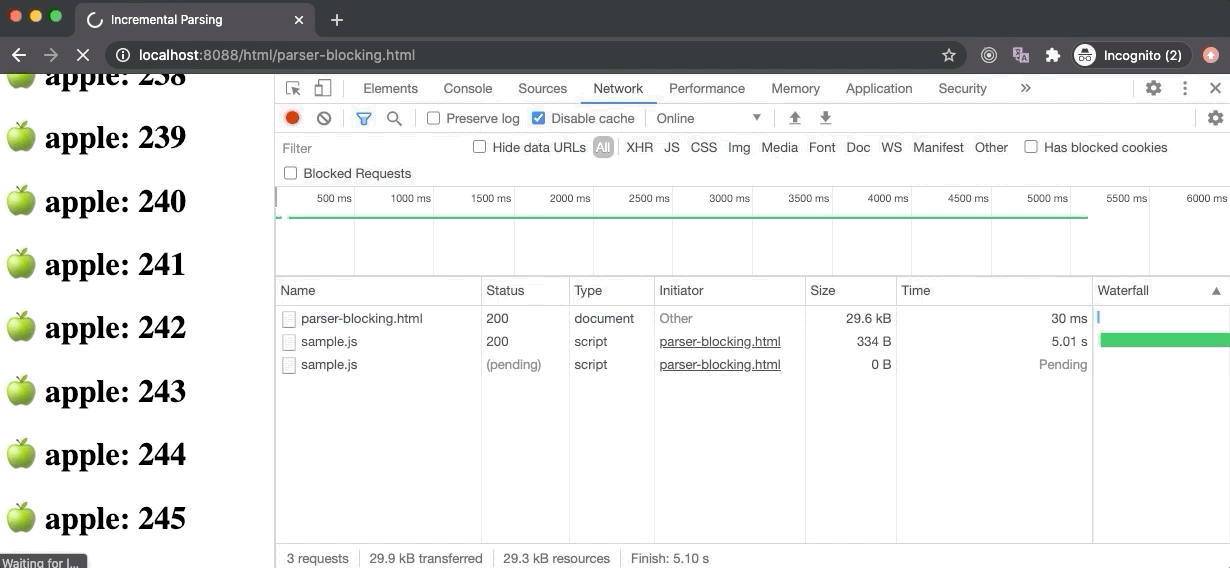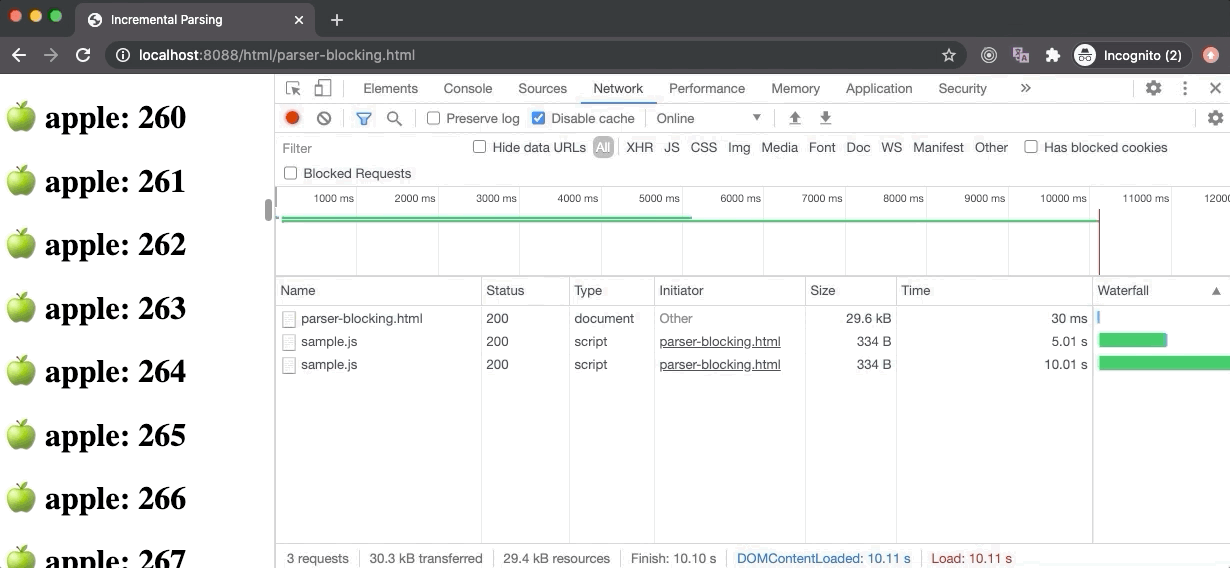
上图中的例子,是 parser-blocking.html 文件,其中包含了30个元素之后的解析阻塞脚本。如果我们看一眼 Performance 面板,其中 FP 和 FCP 都是在 HTML 准备完成尽可能早的开始构建 DOM 树。LCP 在5秒之后开始,这是因为脚本阻塞了 DOM 解析(下载时间),只有30个文本元素被绘制出来。一旦脚本下载和执行完成,DOM 解析便会重新开始。
解析阻塞也被称为渲染阻塞,因为此时渲染也不会进行(渲染需要依赖渲染树,而渲染树依赖 DOM 树)。但是两者还是有一些不同的。
Some browsers may incorporate a speculative parsing strategy where the HTML parsing (but not the DOM tree construction) is offloaded to a separate thread so that browser can read elements such as link(CSS), script, img, etc. and download these resources eagerly.
This is quite helpful if you have three script elements one after the other, but the browser won’t be able to start the download of the second script until the first script is downloaded as the DOM parser couldn’t read the second script element. We can fix this easily by using async tag but asynchronous scripts are not guaranteed to execute in order.
The reason it is called speculative parsing because the browser is making a speculation that a particular resource is expected to load in the future, so better load it now in the background. However, if some JavaScript manipulates DOM and removes/hides the element with an external resource, then speculation fails and these files were loaded for nothing. Tough.
💡 Every browser has a mind of its own, so when or if speculative parsing will happen is not guaranteed. However, you can ask the browser to load some resources ahead of time using the element.
渲染阻塞 CSS
我们了解了,任何除了解析阻塞脚本之外的外部资源请求都是不会阻塞 DOM 解析和树构建的。所以 CSS 并不会阻塞 DOM 解析,等一下,其实是会阻塞的。为了理解这一点,我们需要了解渲染的过程。
DOM 和 CSSOM 树的构建都是在主线程上的,而且这些树时并行进行构建的。它们一起构建出了渲染树,用来绘制元素。这一过程其实也是跟随着 DOM 树的增量构建进行的。
上面谈到 DOM 树的生成时增量生成的(并非一下子生成),也就是浏览器一边解析 HTML 文件,一遍在 DOM 树上增加节点。但是 CSSOM 可不是这样——CSSOM 树的构建并不是增量构建的。
当浏览器遇到 style 嵌入代码块时,它会扫描所有的 CSS 代码,并依据相应的规则更新 CSSOM 树。然后,它会继续解析 HTML 文档,内联的样式也是一样的。
但是外部的样式表就有所不同了。我们知道外部样式表不是解析阻塞资源,所以它能够在后台与 DOM 解析并行地进行下载。但是与脚本不同,浏览器不会在外部样式表下载完后第一时间进行解析,这是因为浏览器无法一边扫描 CSS 文件一边构建 CSSOM 树。原因很简单:CSS 的规则表明,越后面的样式属性,越有可能覆盖前面的属性。一但浏览器增量地生成 CSSOM 树,那么会产生多个渲染树,这会造成很差的体验。
所以浏览器不会增量地生成 CSSOM 树,而是 CSS 文件全部扫描完后才生成完整的 CSSOM。一旦 CSSOM 树生成后,渲染树才会更新并绘制。
CSS 是渲染阻塞资源。一旦浏览器去请求一个外部的样式表文件,渲染树的构建就会暂停(因为渲染树依赖 CSSOM树),因此 CRP(Critical Rendering Path)也会阻塞。但是,DOM 树还是会进行解析。
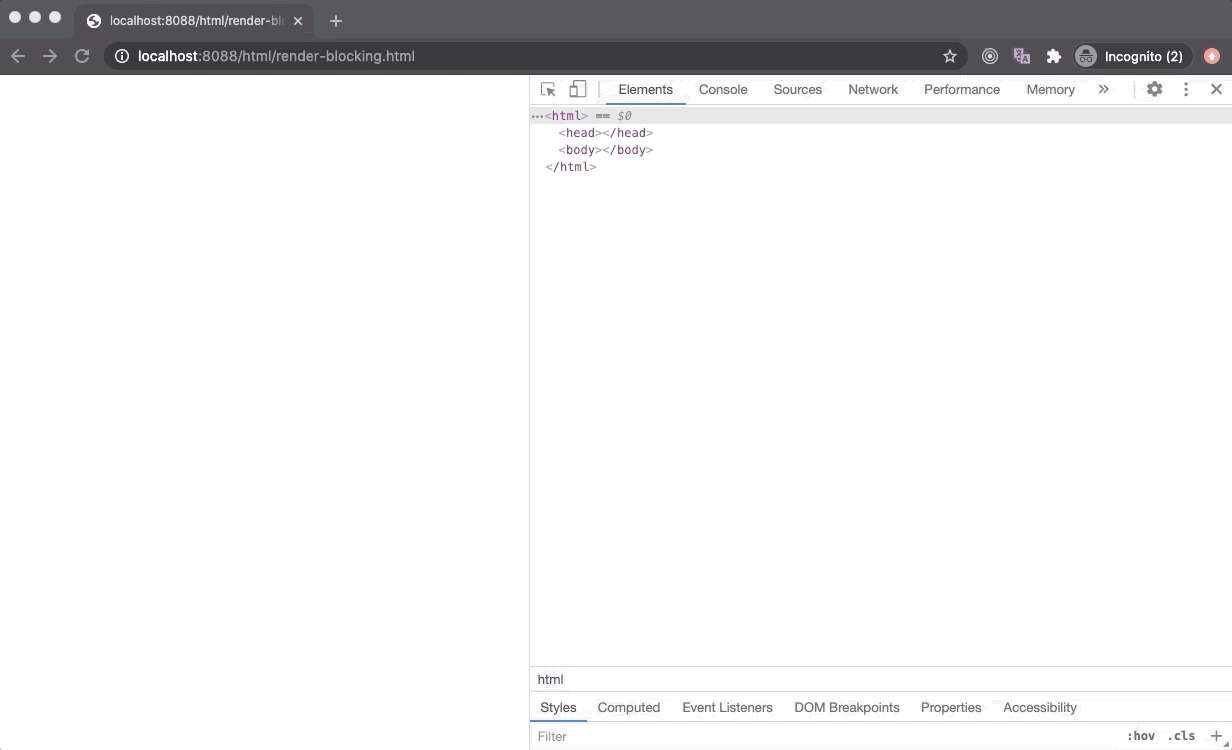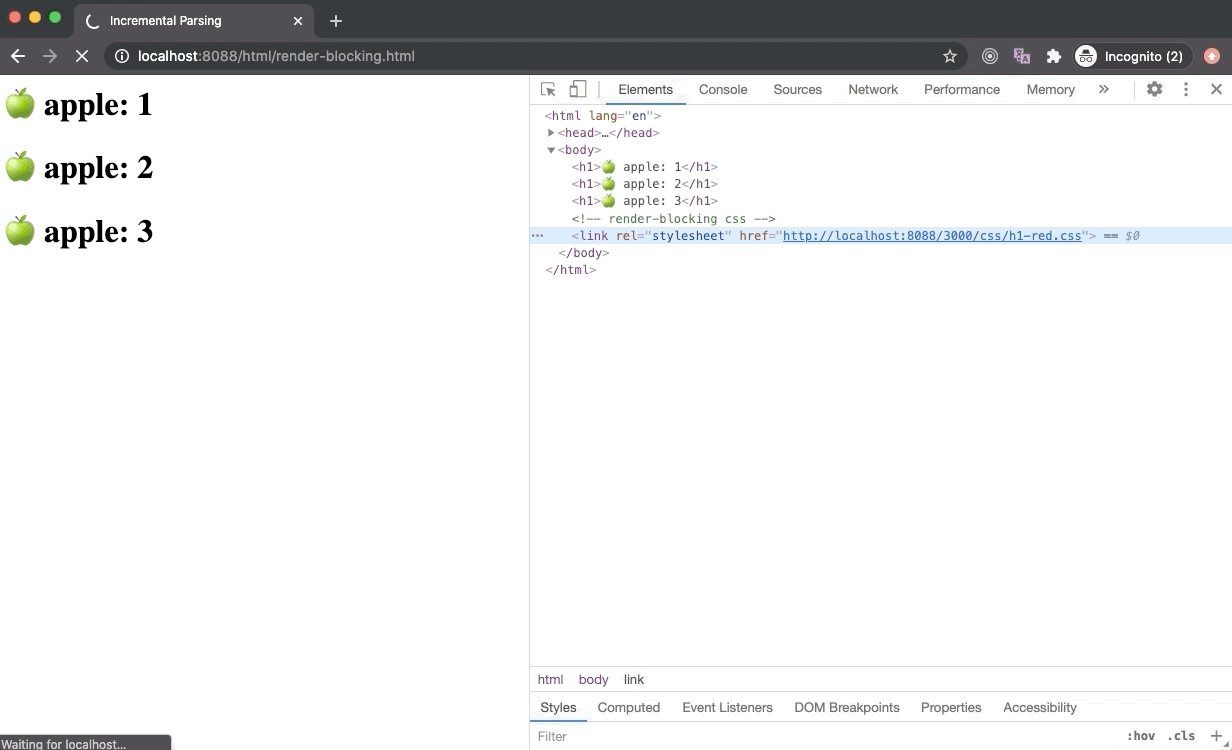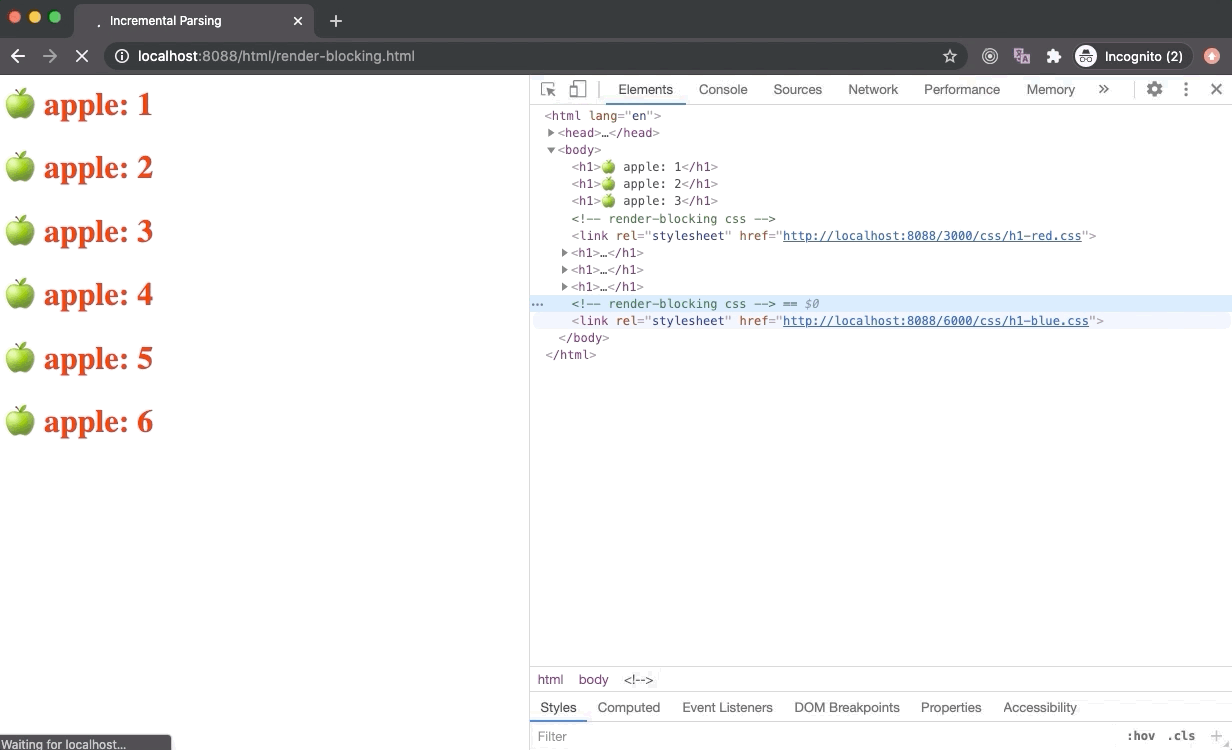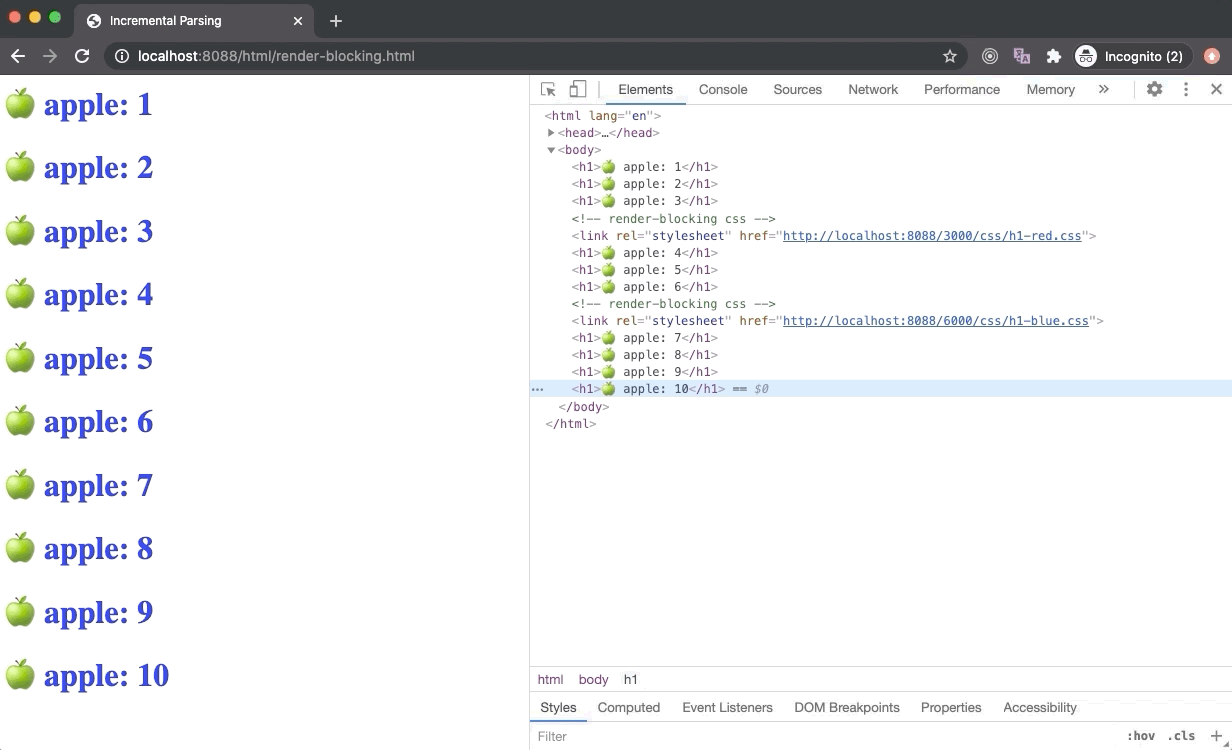
A browser could have used an older state of the CSSOM tree to generate Render Tree as HTML is getting parsed to render things on the screen incrementally. But this has a huge downside. In this case, once the stylesheet is downloaded and parsed, and CSSOM is updated, Render Tree will be updated and rendered on the screen. Now the Render Tree nodes generated with older CSSOM will be repainted with new styles and it could also lead to Flash of Unstyled Content (FOUC) which is is very bad for UX.
Hence browsers will wait until the stylesheet is loaded and parsed. Once the stylesheet is parsed and CSSOM is updated, the Render Tree is updated, and CRP is unblocked which leads to the paint of Render Tree on the screen. Due to this reason, it is recommended to load all external stylesheets as early as possible, possibly in the head section.
Let’s imagine a scenario where the browser has started parsing HTML and it encounters an external stylesheet file. It will start the download of the file in the background, block the CRP, and continue with the DOM parsing. But then it encounters a script tag. So it will start the download of the external script file and block the DOM parsing. Now the browser is sitting idle waiting for the stylesheet and script file to download completely.
But this time, the external script file has been downloaded completely while the stylesheet is still being downloaded in the background. Should the browser execute the script file? Is there any harm doing that?
As we know, CSSOM provides a high-level JavaScript API to interact with the styles of the DOM elements. For example, you can read or update the background color of a DOM element using elem.style.backgroundColor property. The style object associated the elem element exposes the CSSOM API and there are many other APIs to do the same (read this css-tricks article).
As a stylesheet is being downloaded background, JavaScript can still execute as the main thread is not being blocked by the loading stylesheet. If our JavaScript program accesses CSS properties of a DOM element (through CSSOM API), we will get a proper value (as per the current state of CSSOM).
But once the stylesheet is downloaded and parsed, which leads to CSSOM update, our JavaScript now has a bad CSS value of the element since the new CSSOM update could have changed the CSS properties of that DOM element. Due to this reason, it’s not safe to execute JavaScript while the stylesheet is being downloaded.
As per the HTML5 specification, the browser may download a script file but it will not execute it unless all previous stylesheets are parsed. When a stylesheet blocks the execution of a script, it is called a script-blocking stylesheet or a script-blocking CSS.
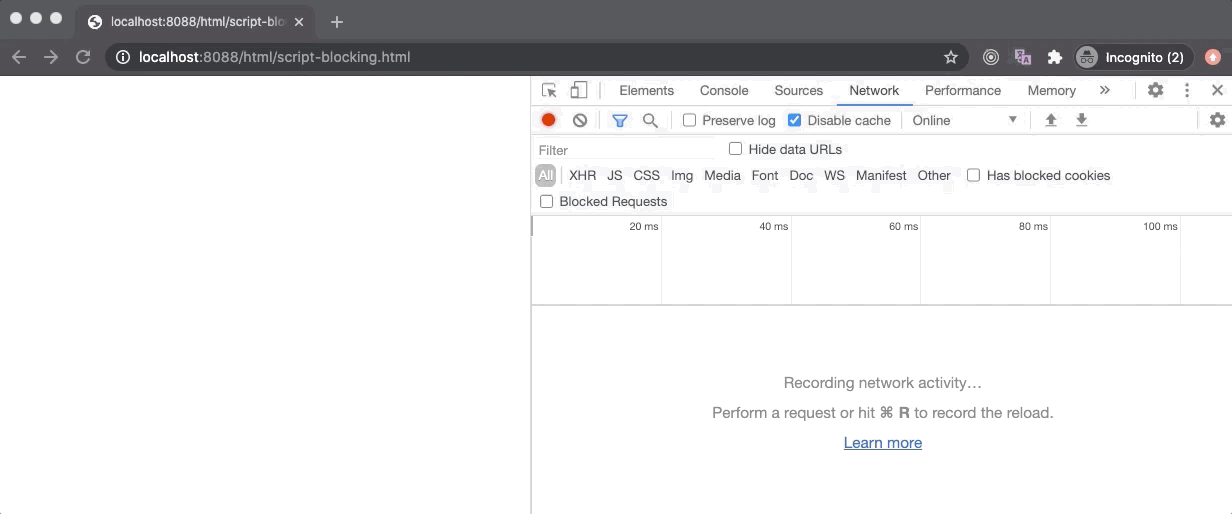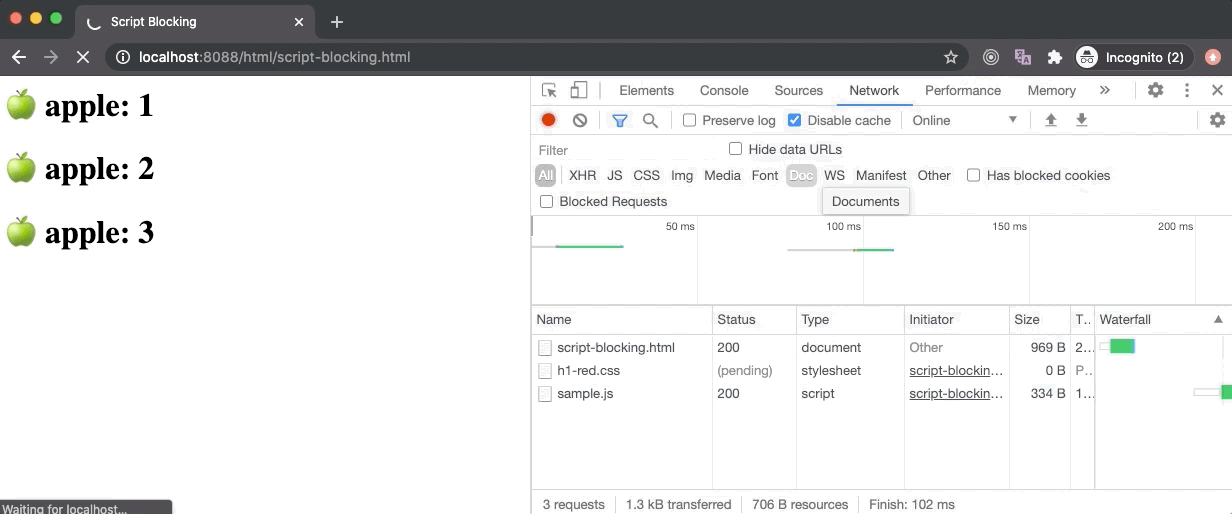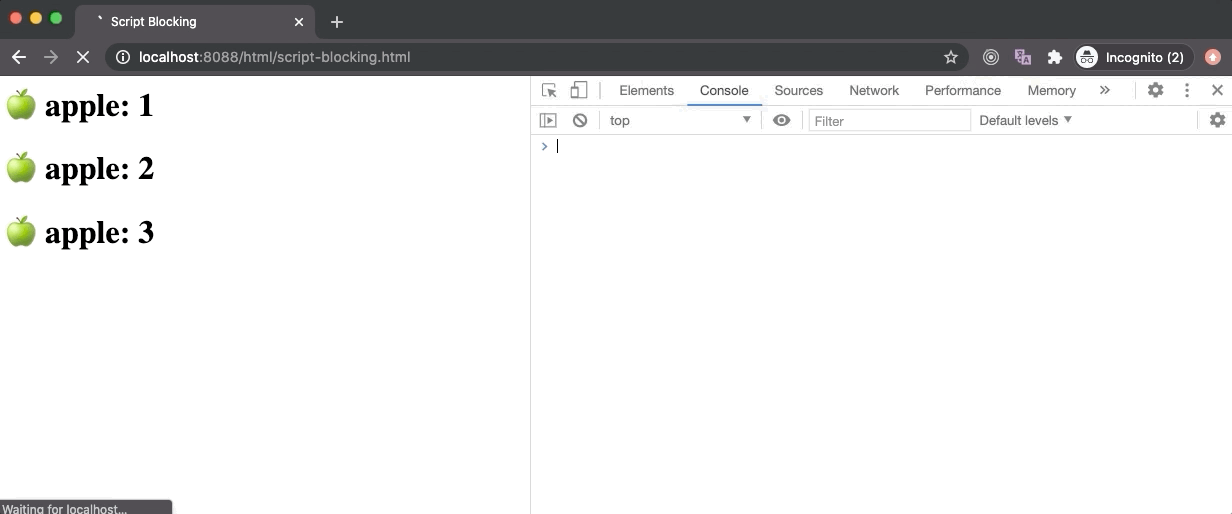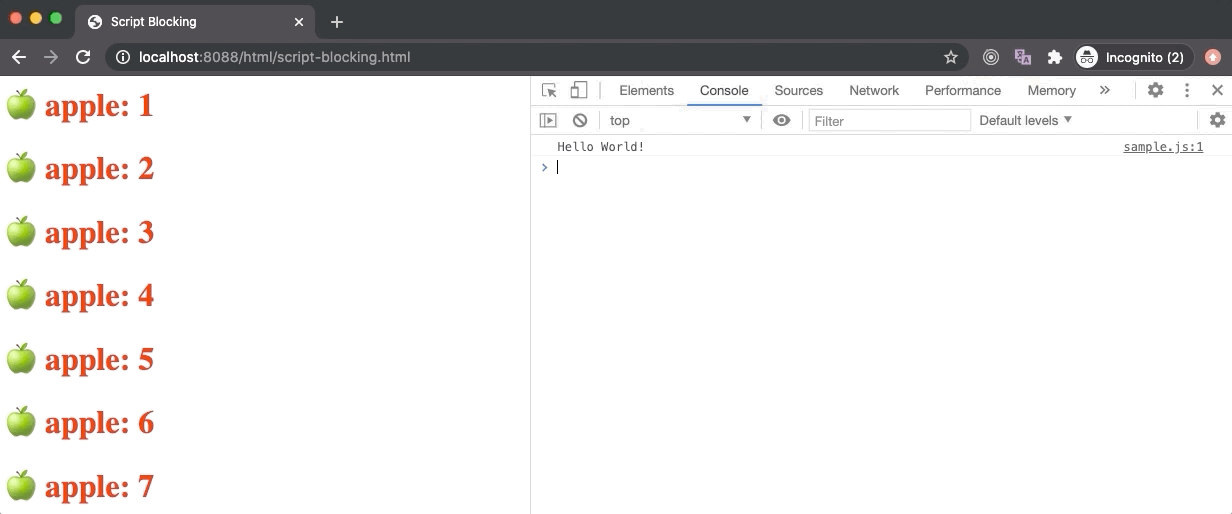
In the above example, the [script-blocking.html](https://github.com/course-one/browser-rendering-test/blob/master/html/script-blocking.html) contains a link tag (for an external stylesheet) followed by a script tag (for an external JavaScript). Here the script gets downloaded really fast without any delay but the stylesheet takes 6 seconds to download. Hence, even though the script is downloaded completely as we can see from the Network panel, it wasn’t executed by the browser immediately. Only after the stylesheet is loaded, we see the Hello World messaged logged by the script.
💡 Like async or defer attribute makes script element non-parser-blocking, an external stylesheet can also be marked as non-render-blocking using the media attribute. Using the media attribute value, the browser can make a smart decision when to load the stylesheet.
Document’s DOMContentLoaded Event
The [DOMContentLoaded](https://developer.mozilla.org/en-US/docs/Web/API/Document/DOMContentLoaded_event) (DCL) event marks a point in time when the browser has constructed a complete DOM tree from all the available HTML. But there are a lot of factors involved that can change when the DCL event is fired.
1 | document.addEventListener( 'DOMContentLoaded', function(e) { |
If our HTML doesn’t contain any scripts, DOM parsing won’t get blocked and DCL will fire as quickly as the browser can parse the entire HTML. If we have parser-blocking scripts, then DCL has to wait until all parser-blocking scripts are downloaded and executed.
Things get a little complicated when stylesheets are thrown into the picture. Even though you have no external scripts, DCL will wait until all stylesheets are loaded. Since DCL marks a point in time when the entire DOM tree is ready, but DOM won’t be safe to access (for the style information) unless CSSOM is also fully constructed. Hence most browsers wait until all external stylesheets are loaded and parsed.
Script-blocking stylesheet will obviously delay the DCL. In this case, since the script is waiting for the stylesheet to load, the DOM tree is not getting constructed.
DCL is one of the website performance metrics. We should optimize the DCL to be as small as possible (the time at which it occurs). One of the best practices is to use defer and async tag for script element whenever possible so that browser can perform other things while scripts are being downloaded in the background. Second, we should optimize the script-blocking and render-blocking stylesheets.
Window’s load event
As we know JavaScript can block DOM tree generation but that’s not the case with external stylesheets and files such as images, videos, etc.
The DOMContentLoaded event marks a point in time when the DOM tree is fully constructed and it is safe to access, the window.onload event marks a point in time when external stylesheets and files are downloaded and our web application (complete) has finished downloading.
1 | window.addEventListener( 'load', function(e) { |
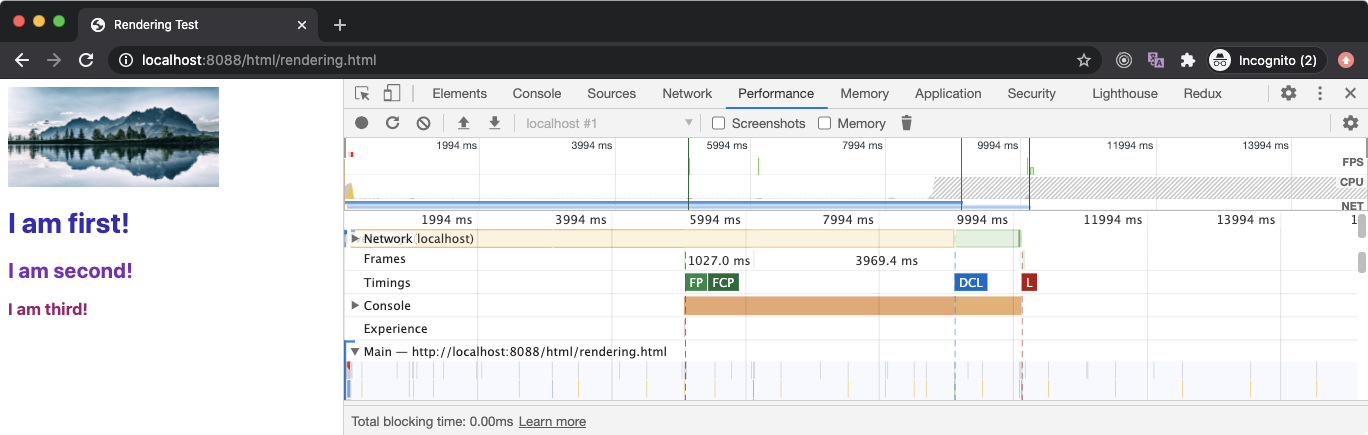
In the above example, the [rendering.html](https://github.com/course-one/browser-rendering-test/blob/master/html/rendering.html) file has an external stylesheet in the head that takes around 5 seconds to download. Since it’s in the head section, the FP and FCP occurs after 5 seconds since the stylesheet will block the rendering of any content below it (as it blocks CRP).
After that, we have an img element that loads an image that takes around 10 seconds to download. So the browser will keep downloading this file in the background and move on with the DOM parsing and rendering (as an external image resource is neither parser-blocking nor render-blocking).
Next, we have three external JavaScript files and they take 3s, 6s, and 9s to download respectively and most importantly, they are not async. This means the total load time should be close to 18 seconds as the subsequent script won’t start downloading before the previous one is executed. However, looking at the DCL event, our browser seemed to have used the speculative strategy to eagerly download the script files so the total time to load is close to 9 seconds.
Since the last file to download that can affect the DCL is the last script file with the load time of 9 seconds (since stylesheet has already been downloaded in 5 seconds), the DCL event occurs around 9.1 seconds.
We also had another external resource which was the image file and it kept loading in the background. Once it was fully downloaded (which takes 10 seconds), the window’s load event was fired after 10.2 seconds which marks that the webpage (application) is fully loaded.